- PERFIL DEL CLIENTE
Zurich Insurance Group, es una aseguradora multinacional que ofrece una amplia gama de productos y servicios de seguros patrimoniales y de vida. Su presencia se encuentra en más de 210 países, otorgando servicios a particulares, Pymes, grandes compañías y multinacionales.
Debido a los grandes cambios en el mercado, es necesario realizar una transformación fundamental, que permita a Zurich mantenerse ágil para ser una empresa exitosa y exceder las expectativas de sus clientes y otros grupos de interés.
- NECESIDADES DEL NEGOCIO
Zurich tiene la necesidad de modernizar su plataforma de Inteligencia de Negocios, que le permita obtener una solución de datos moderna, escalable y flexible. Además, la nueva plataforma debe integrarse con los componentes de tratamiento y almacenamiento de datos que actualmente son utilizados por toda la organización.
Para ello, encomienda a Xemantics el diseño y construcción de la nueva plataforma de Inteligencia de Negocios, teniendo en consideración que ésta impactará transversalmente a todo la organización.
- SOLUCIÓN
Xemantics con su equipo de consultoría, realiza un programa de sesiones de trabajo con cada una de las distintas áreas de negocios y un completo levantamiento de información de la plataforma tecnológica para dimensionar la nueva arquitectura tecnológica que soportará todas las interacciones requeridas por cada usuario.
Los principales esperables del proyecto pretender resolver los siguientes puntos:
- La nueva arquitectura y sus servicios deben estar en la Nube de Azure.
- Poder realizar carga de datos de distintos tipos de orígenes.
- Realizar carga de grandes volúmenes en poco tiempo.
- Monitoreo en línea y efectivo.
- Detalle de la trazabilidad.
- Procesos de carga que se puedan integrar a Control-M y/o Dynatrace,
- Carga de datos a la nube (Transformarlos – Nuevas estructuras – Campos calculados).
- Capacidad de poder definir varios repositorios.
- Definir accesibilidad – usuarios – Granularidad fina.
- Capacidad de definir un repositorio con una vista única con una perspectiva empresarial (SSOT).
- Capacidad de integración con herramientas de Machine Learning (Híbrido).
- Posibilidad de incluir un servicio para abordar la calidad de los datos.
- Evaluar la inclusión de herramientas del tipo Change Data Capture.
- Considerar además la posibilidad de contener metadatos de los procesos.
- Definición de arquitectura e implementación.
- Definición y construcción de modelos (Conciliaciones – Modelo de Recomendaciones – Modelo Actuarial – Entidades Corporativas).
Explotación PowerBI Desktop y Excel.
Para cumplir con la correcta ejecución del proyecto y las necesidades del Cliente, Xemantics confeccionó un modelo de trabajo que abordó las siguientes fases:
- Entorno, necesidad de datos y volumetría
- Flujos de datos
- Definición de áreas, usuarios, sistemas, servidores y servicios involucrados en procesos de BI (habituales y no habituales)4
- Definición e implementación de Arquitectura
- Gobierno de Datos unificado – Purview, Data Factory, Azure Synapse, Power BI y Data Lake
- Modelo de Datos
- Análisis OLTP, construcción de Staging Area, construcción de modelo lógico del DHW, modelos machine learning y Dashboard.
- Aplicación de seguridad y normativas legales
- ASPECTOS TÉCNICOS
La arquitectura contempla una solución basada en la nube de Microsoft Azure, con diversos servicios asociados a los objetivos y requerimientos planteados por el área BI de Zurich Chile y descritos en este documento.
La arquitectura presenta un escenario On Premise, que corresponde a los orígenes de datos desde donde se extrae la información necesaria que contendrán los modelos. Adicionalmente también cuenta con 3 componentes de tipo proxy albergados en 3 máquinas distintas para la conexión que necesita establecer Data Factory, Purview y PowerBi con los servicios de Azure, además de un cuarto servidor dedicado para machine learning.
En Azure se concentran los servicios necesarios que almacenarán los datos separados lógicamente entre los datos crudos, procesados y por procesar además de los modelos, gobierno y trazabilidad de estos, visualización y limpieza.
Desde la perspectiva de seguridad existirá una red privada entre On Premise y Azure con cada uno de los componentes involucrados, con la finalidad de que los datos solo se puedan manejar y visualizar en el ámbito de la red Zurich. La interconexión se realiza a través de Palo Alto – Express Route.
A continuación se describen los principales componentes y servicios desde la perspectiva de Azure.
- COMPONENTES PRINCIPALES
- On – Premise: son todos los orígenes en los data center de Zurich que permiten extraer metadatos y datos necesarios para el gobierno y modelos.
- Integration Runtime: es un componente del tipo proxy que permite la comunicación entre los orígenes de datos y los servicios de Data Factory y Purview.
- TDE: Transparent Data Encryption. Permite la encriptación de bases de datos a través de llaves en caso de perdida y mal utilización de estas.
- TLS: Transport Layer Security. Permite la encriptación de los datos a nivel de transporte de estos (viaje seguro)
- Azure Data Lake: Contenedor de archivos en Azure optimizado para tareas de BI y analítica principalmente.
- Azure Purview: Servicio que permite el gobierno de datos en virtud de la trazabilidad y linaje de estos. También permite la clasificación y agrupación de estos.
- Azure Synapse: Servicio que reúne bases de datos SQL Server, Azure Data Factory y ejecución de procesos en Spark optimizados para tareas de BI y Analítica Avanzada.
- Power BI: Servicio que permite la realización de Dashboard y reportes a partir de los datos.
- Azure Machine Learning: Servicio y entorno de desarrollo que permite la confección de analítica avanzada a partir de modelos predictivos.
- FLUJO GENERAL DE DATOS PARA LA SOLUCIÓN
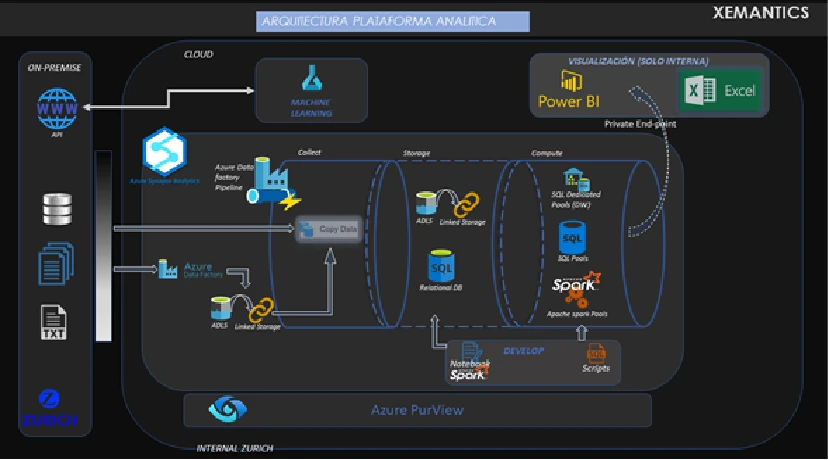
Este flujo representa un diagrama general a ser utilizado en cualquier modelo, procesamiento y/o reporte que se requiera como parte de las actividades a realizar por el área BI de Zurich.
Los orígenes de datos que están ubicados On premise y que pueden ser de múltiples formatos, son copiados a través de distintos flujos de datos (DF) requeridos a un área de Data Lake, Azure SQL, etc. o cualquier servicio requerido según los requerimientos de la información.
Según la naturaleza de los datos que pueden responder a un modelo o necesidades particulares de un área y/o de forma aislada como archivos de texto, csv, u otros, son copiados y limpiados a su área de residencia que eventualmente podría ser nuevamente Data Lake, Azure SQL, etc.
A su vez también existe la posibilidad que estos datos también necesiten de cómputos más exhaustivos en términos de procesamiento, como es el caso de escenarios de analítica avanzada y Machine Learning para lo cual es posible ejecutar en escenarios de SQL Data Pool dedicados, Spark para depuración de Data.
Una vez realizadas las tareas sobre los datos y almacenados se realizan los reportes bajo Power BI según necesidad.
Los datos desde su origen hasta su destino son trakeados a través de Purview para tener observabilidad, clasificación y gobierno sobre los datos.
- FLUJO DE DATOS POR MODELO
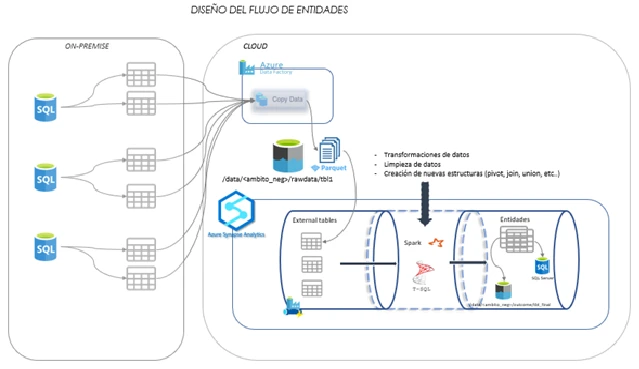
El modelo de E.C. requiere la utilización de los datos crudos, de la misma forma que se utilizan en su origen On Premise, por lo que se ejecutan Data Factory y se almacenan en Data Lake. Una vez almacenado se transforman y limpia la información según necesidad, aplicando también las reglas de cada entidad. A partir de la información resultante se dispone cada entidad en Data Lake y SQL Data Pool. Las entidades quedan disponibles para ser consultadas como tablas externas y cruzar con información necesaria complementaria de otros modelos / data como parte de Azure Synapse.
El modelo de E.C. requiere la utilización de los datos crudos, de la misma forma que se utilizan en su origen On Premise, por lo que se ejecutan Data Factory y se almacenan en Data Lake. Una vez almacenado se transforman y limpia la información según necesidad, aplicando también las reglas de cada entidad. A partir de la información resultante se dispone cada entidad en Data Lake y SQL Data Pool. Las entidades quedan disponibles para ser consultadas como tablas externas y cruzar con información necesaria complementaria de otros modelos / data como parte de Azure Synapse.
El modelo de conciliación tiene requerimientos que por su naturaleza, su modelo se almacena directamente en un SQL Data Pool. A partir de los orígenes de datos y se generan los Pipeline necesarios donde se aplican directamente las reglas de negocios necesarias para el modelo. Eventualmente se podrán disponer de tablas en un directorio común de Data Lake para auto consumo por otros usuarios y combinación con otras tablas externas.
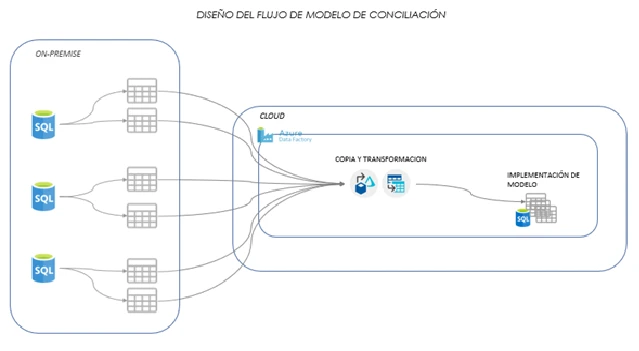
A partir del modelo y los datos almacenados se confecciones y realizan en Power BI para las visualizaciones.
- Modelos predictivos
Como parte de la solución, también se realizó la implementación de modelos predictivos de recomendación. Puedo ver el detalle como parte de nuestras soluciones en el siguiente link (link a soluciones->Modelos de Recomendación)
- RESULTADOS ESPERADOS
La nueva plataforma de inteligencia de negocios otorga mejoras sustanciales y agilidad en la identificación de nuevas oportunidades y mantención de clientes, logrando gestionar grandes volúmenes de información, permitiéndoles a las distintas áreas gerenciales definir nuevas estrategias de venta y mantención para la sustentabilidad del negocio. En cuanto al área de tecnología TI, la fácil administración y seguridad de datos ha permitido proveer una continuidad de los servicios, obteniendo un retorno de la inversión en muy breve tiempo.